
On this page
The Only Blog You’ll Ever Need to Master Kubernetes Health Checks

Introduction
Kubernetes is one of the most powerful tools for orchestrating containerized applications.
When it comes to healthchecks Kubernetes offers multiple options. Its very important to understand these healthcecks so that you can deploy a resilient and highly available application.
Kubernetes healthchecks can be confusing. For most beginners, all the healthchecks sound the same. After reading this blog - your confusion about healthchecks will be cleared forever.
Kubernetes provides the following healthchecks (It calls them Probes)
- Readiness Probe,
- Liveness Probe
- Startup Probe.
Each one plays a unique role in managing the lifecycle and health of your application
In this blog, we’ll walk through these probes, their real-world use cases, how they help solve critical industry problems, and best practices for configuring them.
Readiness Probe: Is Your App Ready to Serve Traffic?
What is a Readiness Probe?
The readiness probe ensures that your application is prepared to receive traffic. Even if your application is running, it may not always be able to handle incoming requests right away. This can happen if the application is still initializing, loading data, or waiting on external services like databases.
The readiness probe acts as a gatekeeper, blocking traffic until your app signals that it’s ready.
Consider a large-scale e-commerce platform with multiple microservices handling various tasks like payments, inventory management, and user authentication. One of these services (e.g., the payments service) might take time to connect to a third-party payment gateway or database during startup.
Without a readiness probe, Kubernetes might start routing traffic to the service before it’s fully connected, leading to failed transactions. This can result in a poor user experience or financial loss.
How Readiness Probes Solve the Problem
A readiness probe can be used to delay the traffic to the payment service until it establishes all necessary connections. This ensures that traffic only flows when the service is ready to process requests.
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
In this example, Kubernetes will check the /ready endpoint of the service to determine if it’s ready to serve traffic. The initialDelaySeconds parameter gives the app time to start before Kubernetes starts probing.
Best Practices for Readiness Probes
- Tune probe intervals: Make sure your probe intervals reflect the real-world startup time of your app. Too short a delay might result in traffic being routed prematurely.
- Test your probe in staging: Misconfigured probes can cause issues in production. Always test them in a controlled environment.
Liveness Probe: Should the application be Killed?
What is a Liveness Probe?
A liveness probe monitors whether your application is still alive and functioning. Sometimes, apps might crash or get stuck in a deadlock state, where they stop responding but don’t exit. In such cases, Kubernetes can restart the container using the liveness probe to restore the app’s functionality.
A major SaaS company ran a microservice-based architecture for managing user data and encountered memory leaks in its Java-based service. The app would occasionally stop responding because it ran out of memory, but the process wouldn’t terminate. Without a liveness probe, Kubernetes had no way of knowing the service was dead, leaving it unresponsive until manual intervention.
How Liveness Probes Solve the Problem
A liveness probe ensures that if the Java app gets stuck due to a memory leak, Kubernetes will detect this and restart the container. This automatic restart prevents downtime and reduces the need for manual monitoring.
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 10
periodSeconds: 30Kubernetes checks the /health endpoint every 30 seconds to ensure the service is alive. If the service doesn’t respond, Kubernetes restarts it.
Best Practices for Liveness Probes
- Set realistic thresholds: Don’t configure probes to check too frequently, as this may lead to unnecessary restarts.
- Use different types of probes: Liveness probes can be command-based, HTTP-based, or TCP-based. Choose the one that suits your application’s architecture.
Startup Probe: Giving Your App Time to Get Started
What is a Startup Probe?
While the readiness and liveness probes focus on an app’s ongoing state, the startup probe is concerned with the application’s initial state. It allows you to define a probe that checks whether the application has successfully started before allowing other probes to take over.
Real-World Problem: Java Applications with Slow Startups
Certain applications, such as those written in Java, may take a long time to start due to the need to load multiple libraries and initialize complex services. Without a startup probe, Kubernetes may assume the app is failing during startup and restart it prematurely.
How Startup Probes Solve the Problem
A startup probe ensures that Kubernetes gives the application enough time to initialize. This is especially useful in environments where certain apps have longer startup times.
startupProbe:
httpGet:
path: /start
port: 8080
initialDelaySeconds: 60
periodSeconds: 10
Kubernetes checks the /start endpoint after a delay of 60 seconds to confirm the app has started properly before allowing other probes to take over.
Best Practices for Startup Probes
- Use startup probes with apps that require heavy initialization: Complex services, particularly those involving databases or third-party APIs, benefit from startup probes.
- Set proper timeouts: Ensure the startup probe gives your app enough time to initialize without triggering unnecessary restarts.
Common Pitfalls and How to Avoid Them
Probe Timing Issues
One common issue teams face is misconfiguring the intervals and timeouts for probes. If your probes check too frequently, they may trigger unnecessary restarts. If they check too slowly, they may not catch failures in time.
Relying on Only One Probe
While readiness, liveness, and startup probes each have their use cases, relying on only one probe can cause problems. For example, using a liveness probe without a readiness probe might result in traffic being routed to an app that’s not yet ready.
Balancing Probe Sensitivity and Overhead
Every probe adds some overhead. Over-probing can negatively impact your app’s performance, so it’s important to find the right balance.
YAML Configurations for All Probes in Complex Applications
Here’s a full example of a Kubernetes pod configuration with all three probes (readiness, liveness, startup) for a complex microservices architecture:
containers:
- name: app-container
image: myapp:latest
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 10
startupProbe:
httpGet:
path: /start
port: 8080
initialDelaySeconds: 60This configuration ensures that the application is fully started before checking readiness and liveness.
Question & Answer Section
- Q: What happens if the startup probe fails?
- A: Kubernetes will terminate and restart the container if the startup probe fails, as it assumes the app cannot start.
- Q: Should I configure different probes for different environments (dev vs. prod)?
- A: Yes. In development, you may want faster probe intervals to catch issues early. In production, longer intervals can help reduce unnecessary restarts.
- Q: How do I know when to adjust probe timings?
- A: You can analyze application logs and performance data to find the right timing for probes. Always test probes in a staging environment before applying them to production.
- Q: Can probes impact application performance?
- A: If misconfigured, probes can add unnecessary load to your app. Use reasonable intervals to avoid this.
Conclusion
Here’s a quick comparison on readiness, liveness, and startup probes in Kubernetes:
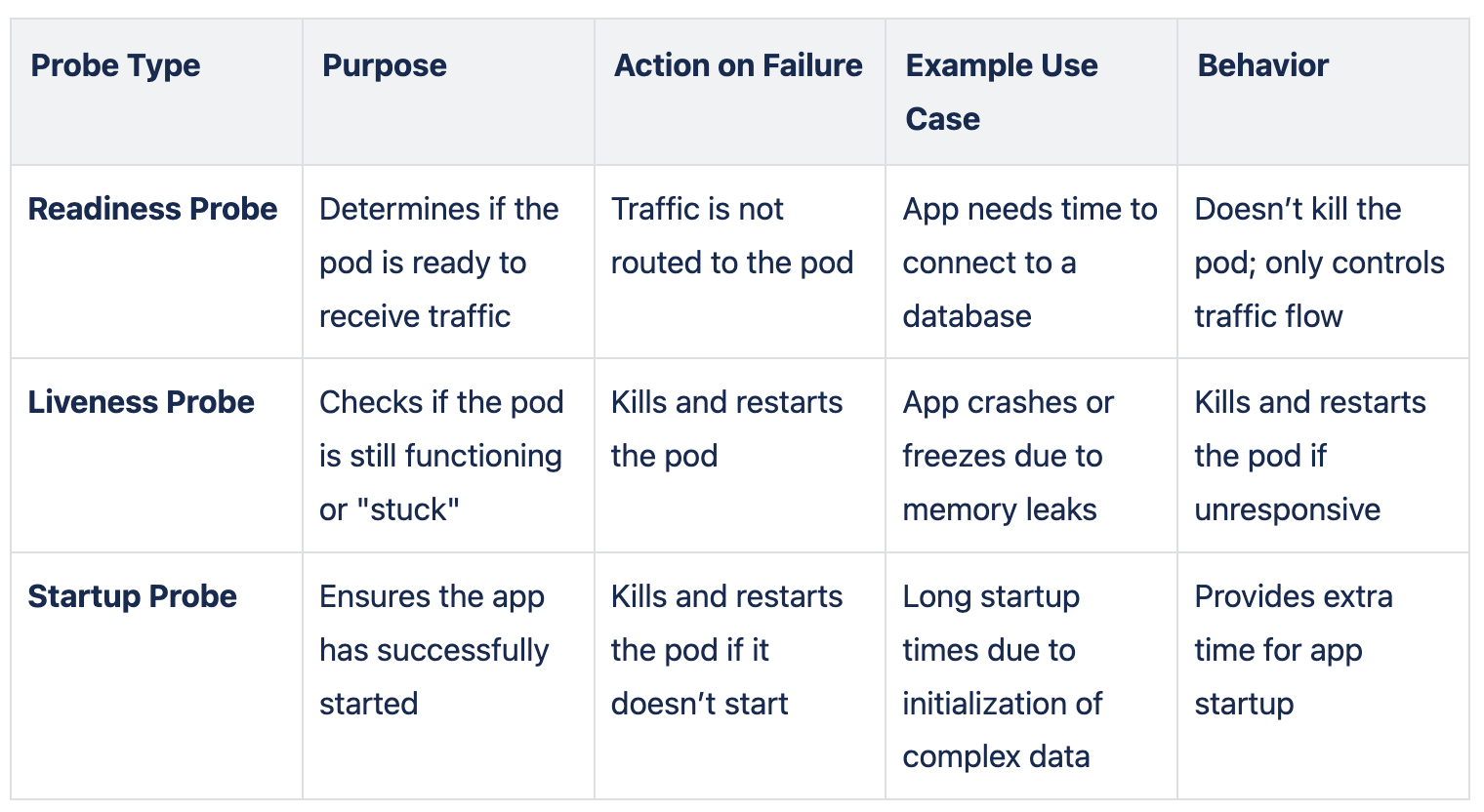
Health checks are clearly important for every application. The good news is that they are easy to implement and, if done properly, enable you to troubleshoot issues faster. If you log exactly why a health check failed, you can pinpoint and solve issues easily.
Checkout our article on all the new features in Kubernetes 1.30 at: https://www.kubeblogs.com/explore-all-the-new-features-in-kubernetes-1-30/