
On this page
The art of zero-downtime in kubernetes : Deployment Strategies

Introduction
Imagine you're running a popular online service, and suddenly, during an update, your application goes down. Users can't access your service, and with each passing minute, you're losing revenue and customer trust. This scenario is every developer's nightmare. Downtime not only frustrates users but can also lead to significant financial losses and damage to your company's reputation.
For example, major companies like Google have faced issues when their services experienced downtime, leading to widespread user dissatisfaction and financial impact. Avoiding such situations is crucial for any business striving for excellence.
So, how can we update our applications without causing any interruptions? The answer lies in effective deployment strategies that allow for zero downtime. In this blog, we'll explain step by step how to achieve zero downtime using Kubernetes deployment strategies.
Understanding Deployment Strategies
There are several deployment strategies available, but we'll focus on the three main ones that are widely used and proven to be effective:
- Rolling Updates
- Blue/Green Deployments
- Canary Deployments
Each of these strategies offers a different approach to deploying applications without downtime. We'll delve into each one, explain how they work, and help you decide which is the best fit for your needs.
Rolling Updates
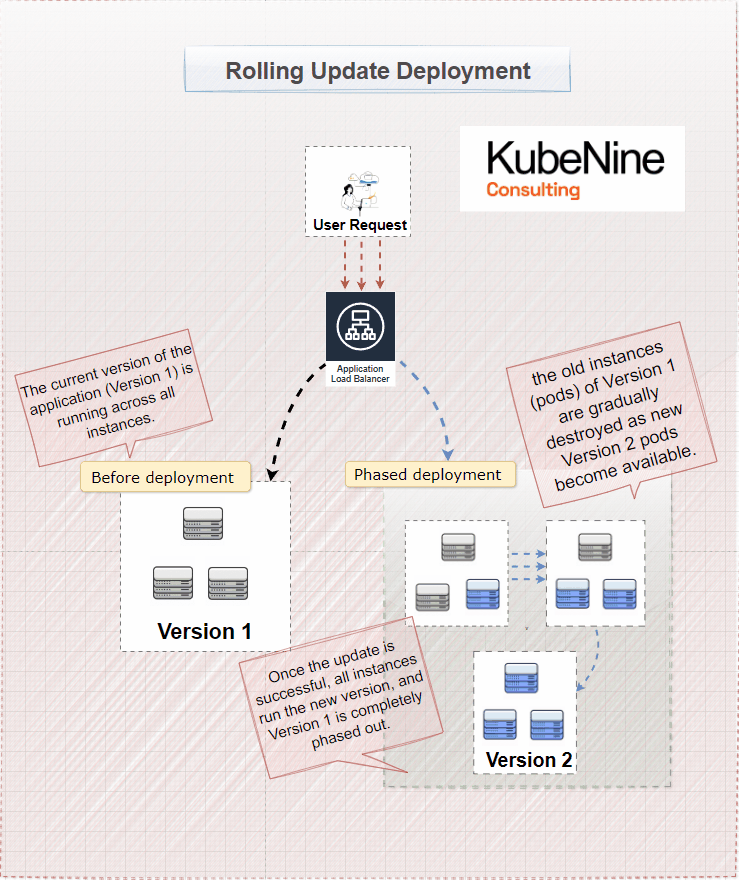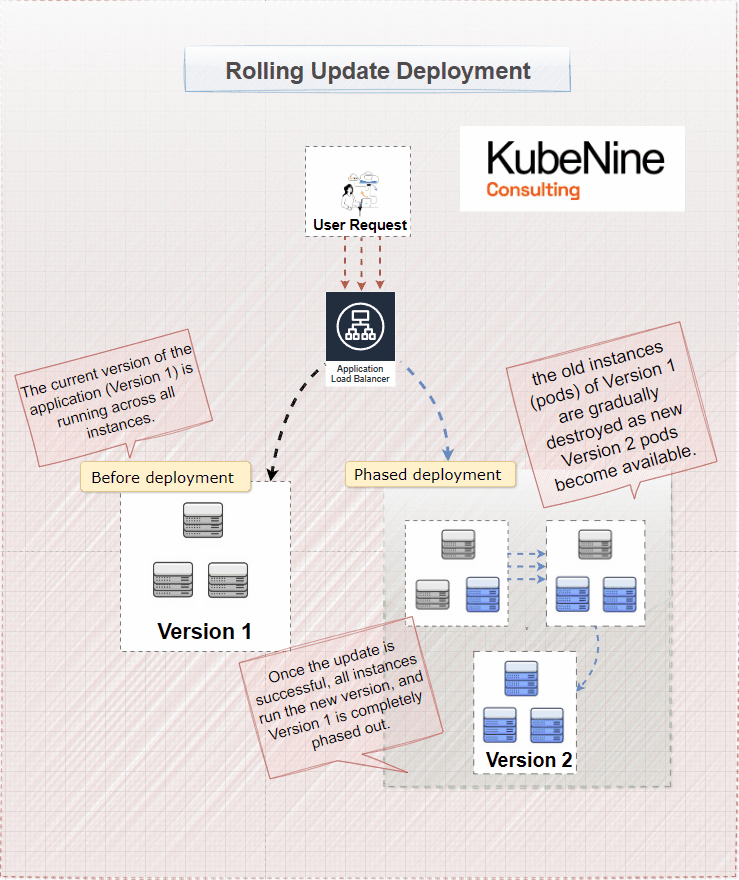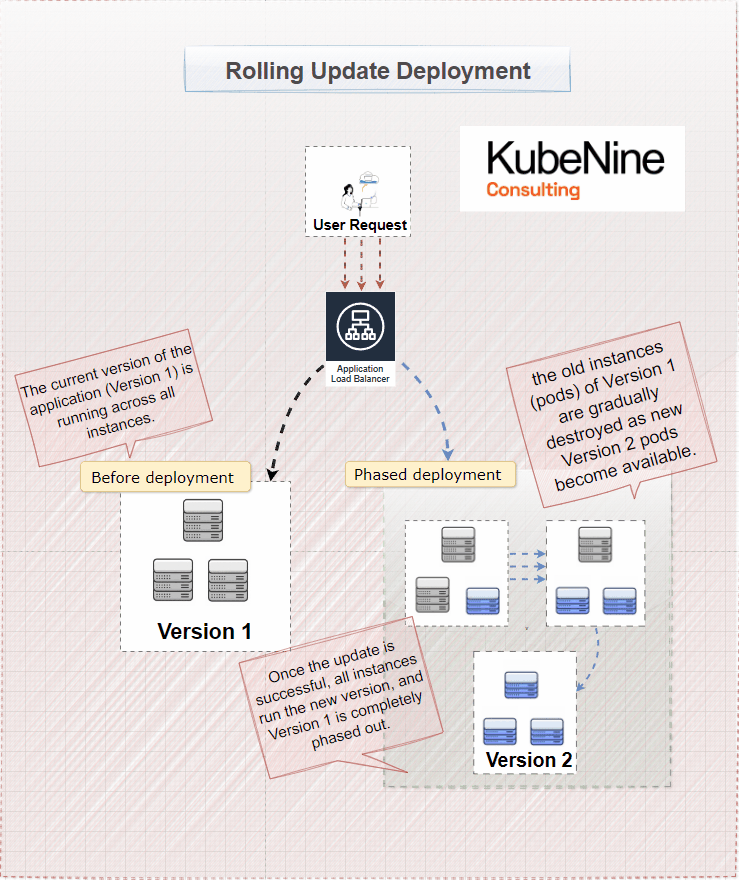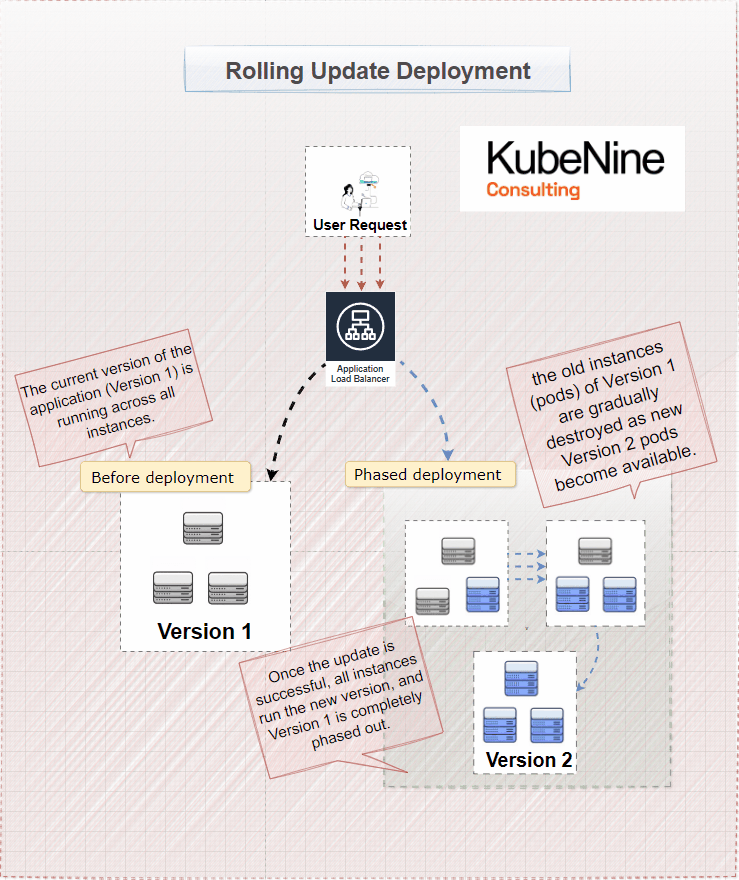
What Are Rolling Updates?
Rolling updates are the default deployment strategy in Kubernetes. They allow you to update your application incrementally, without taking the entire service offline. Instead of updating all instances of your application at once, you replace them one by one.
Example: Suppose Google wants to update its search algorithm. Instead of updating all servers simultaneously, they update them gradually to make sure the service remains available and to monitor the impact of the changes.
How Rolling Updates Work
- Gradual Replacement: Kubernetes replaces old pods with new ones incrementally.
- Maintaining Availability: At any given time, most pods are still serving the application, so users aren't affected.
- Monitoring: You can watch each new pod as it's deployed to catch any issues early.
YAML Configuration Example
Here's how you might set up a rolling update for your application:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 4
selector:
matchLabels:
app: my-app
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1 # Max pods that can be unavailable during the update
maxSurge: 1 # Max extra pods over desired number
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app-container
image: my-app:v2 # New version of your appExplanation of Key Parameters:
- maxUnavailable: Specifies the maximum number of pods that can be unavailable during the update process. Setting it to 1 ensures that at least 3 pods are always running.
- maxSurge: Specifies the maximum number of pods that can be created above the desired number of replicas. Setting it to 1 allows Kubernetes to bring up a new pod before terminating an old one.
Handling Issues During Rolling Updates
If a new version causes problems:
- Automatic Rollback: Kubernetes can detect failures and halt the update.
- Manual Intervention: You can use
kubectl rollout undo deployment/my-appto roll back to the previous version. - Debugging: Use logs and monitoring tools to identify and fix issues before proceeding.
Pros and Cons
Pros:
- Zero Downtime: Users experience no interruption.
- Resource Efficient: Doesn't require additional infrastructure.
- Early Issue Detection: Problems can be spotted early in the update process.
Cons:
- Slower Deployment: Updates take longer as they are done incrementally.
- Potential Exposure: If an issue isn't detected early, it can affect users as the rollout progresses.
Is Rolling Update Right for You?
Rolling updates are ideal for most applications where gradual updates are acceptable, and you want to minimize resource usage. It's a solid choice for services that can tolerate incremental changes.
Blue/Green Deployments
What Are Blue/Green Deployments?
Blue/Green deployments involve running two identical environments called Blue and Green. One environment (Blue) serves all the production traffic, while the other (Green) is where you deploy and test your new version. Once the new version is ready, you switch traffic to the Green environment.
Example: Suppose Google wants to launch a new version of Gmail. They deploy the new version to the Green environment, test it thoroughly, and when confident, switch user traffic from the Blue to the Green environment.
How Blue/Green Deployments Work
- Deploy to Green Environment: The new version is deployed to the idle environment (Green).
- Testing: The Green environment is thoroughly tested to confirm it's functioning correctly.
- Switching Traffic: Traffic is redirected from Blue to Green, making the new version live.
- Monitoring: After the switch, the new environment is observed for any issues.
- Rollback Plan: If issues arise, traffic can be switched back to the Blue environment.
YAML Configuration Example
Blue Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app-blue
spec:
replicas: 4
selector:
matchLabels:
app: my-app
version: blue
template:
metadata:
labels:
app: my-app
version: blue
spec:
containers:
- name: my-app-container
image: my-app:v1
Green Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app-green
spec:
replicas: 4
selector:
matchLabels:
app: my-app
version: green
template:
metadata:
labels:
app: my-app
version: green
spec:
containers:
- name: my-app-container
image: my-app:v2
Service Configuration:
apiVersion: v1
kind: Service
metadata:
name: my-app-service
spec:
selector:
app: my-app
version: blue # Change to 'green' to switch traffic
ports:
- protocol: TCP
port: 80
targetPort: 80
Switching Traffic
To switch users to the Green environment:
- Update the Service Selector: Change
version: bluetoversion: greenin the service definition. - Apply the Updated Service: Use
kubectl apply -f service.yamlto update the service. - Monitor the Deployment: Ensure that users are accessing the new version without issues.
Handling Issues
If problems occur after the switch:
- Rollback Quickly: Change the service selector back to
version: blueto redirect traffic back. - Investigate and Fix: Identify the issues in the Green environment, fix them, and repeat the process.
Pros and Cons
Pros:
- Zero Downtime: Users are seamlessly switched to the new version.
- Easy Rollback: Switching back to the old version is straightforward.
- Isolation: Testing is done in an environment identical to production.
Cons:
- Resource Intensive: Requires double the resources to run two environments.
- Complexity: Managing two environments can be challenging.
- Cost: Higher infrastructure costs due to increased resource usage.
Is Blue/Green Right for You?
Blue/Green deployments are suitable for critical applications where downtime is unacceptable, and you have the resources to support two environments. It's ideal when you need a safe and quick rollback mechanism.
Canary Deployments
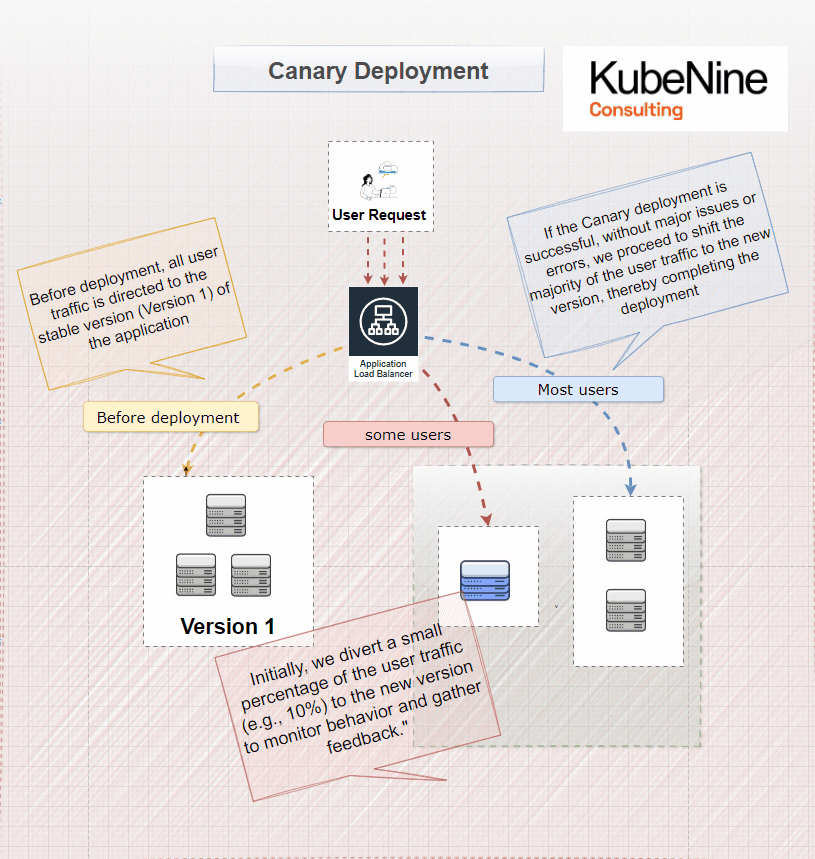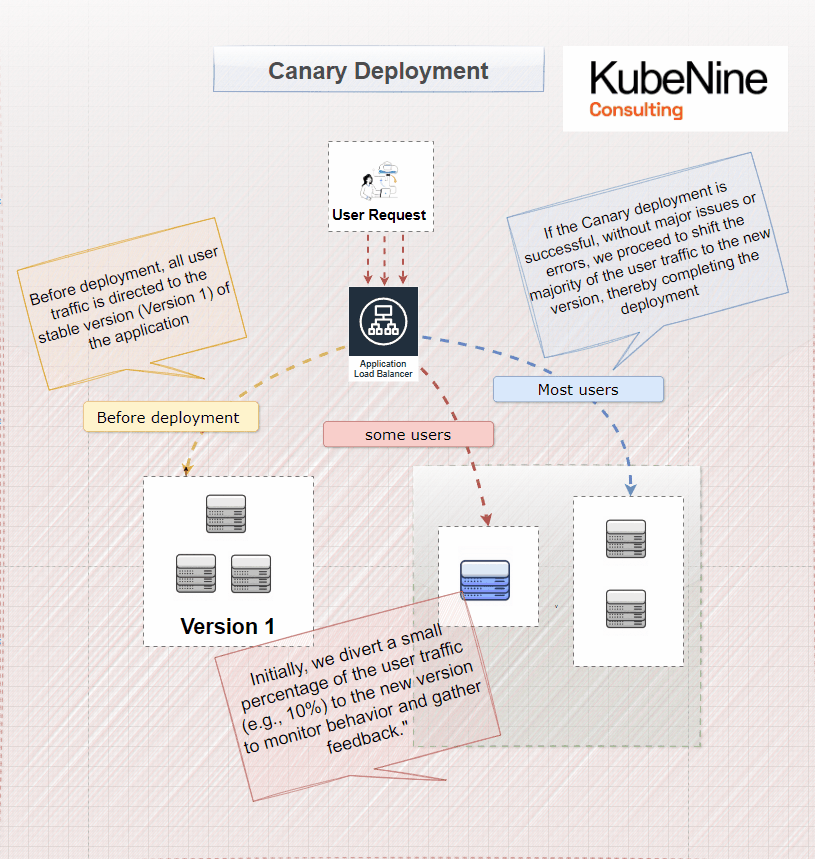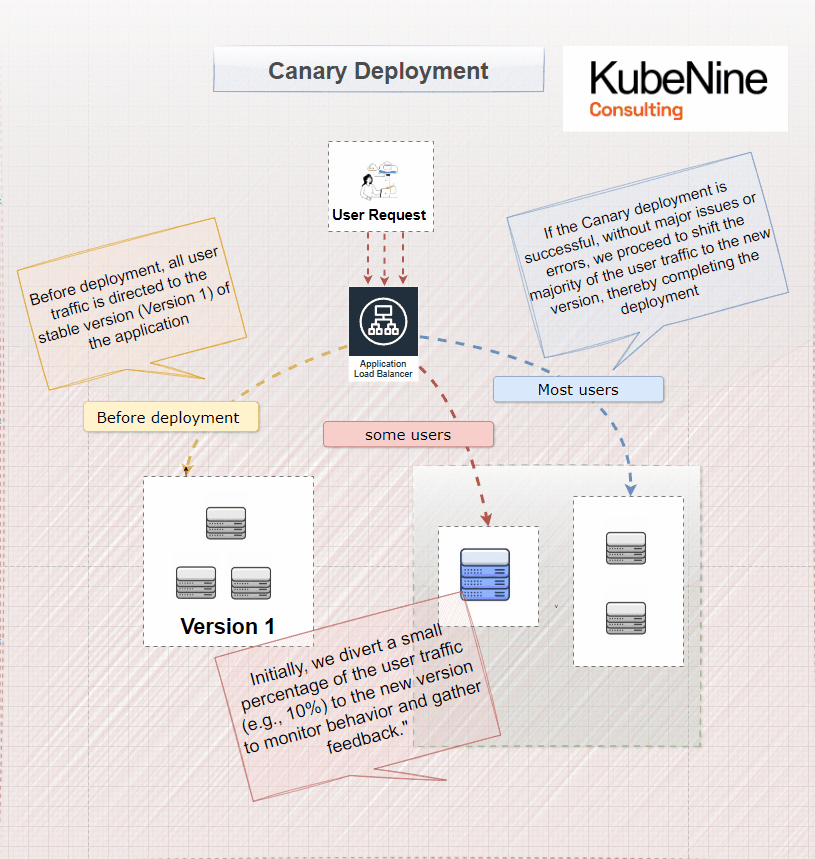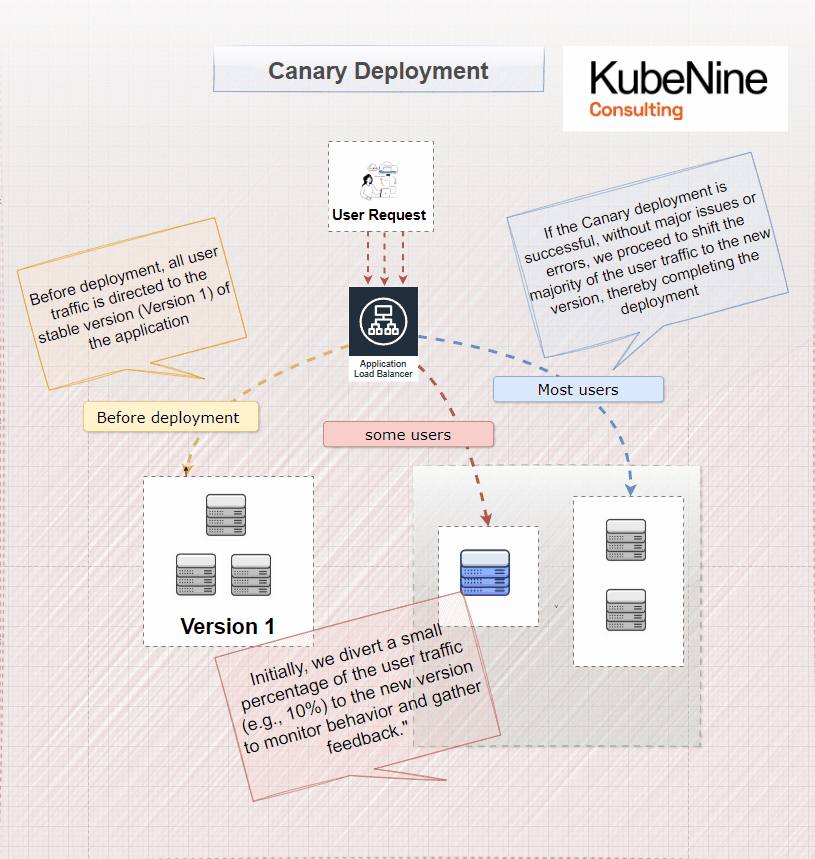
What Are Canary Deployments?
Canary deployments involve rolling out the new version to a small subset of users before making it available to everyone. This strategy allows you to test the new version in a real-world environment with minimal risk.
Example: Google may release a new feature in Google Maps to a small percentage of users to gather feedback and monitor performance before a full rollout.
How Canary Deployments Work
- Deploy New Version Alongside Old: Both versions run simultaneously.
- Route Partial Traffic: A small percentage of users are routed to the new version.
- Monitor Performance: Collect data on how the new version is performing.
- Gradual Rollout: If successful, increase the percentage of traffic to the new version.
- Full Deployment: Eventually, all users are served the new version.
YAML Configuration Example
Stable Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app-stable
spec:
replicas: 9
selector:
matchLabels:
app: my-app
version: stable
template:
metadata:
labels:
app: my-app
version: stable
spec:
containers:
- name: my-app-container
image: my-app:v1Canary Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app-canary
spec:
replicas: 1
selector:
matchLabels:
app: my-app
version: canary
template:
metadata:
labels:
app: my-app
version: canary
spec:
containers:
- name: my-app-container
image: my-app:v2Traffic Routing
Standard Kubernetes services don't support advanced traffic splitting based on percentages. To achieve this, you can use additional tools like Istio or Linkerd.
Using Istio for Traffic Splitting:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: my-app
spec:
hosts:
- "my-app.example.com"
http:
- route:
- destination:
host: my-app
subset: stable
weight: 90
- destination:
host: my-app
subset: canary
weight: 10Monitoring and Adjusting
- Continuous Monitoring: Use monitoring tools to observe the performance of the canary version.
- User Feedback: Collect feedback from users experiencing the new version.
- Adjust Traffic: Based on the data, decide whether to increase traffic to the new version or roll back.
Handling Issues
If issues are detected:
- Reduce or Stop Traffic: Adjust the traffic routing to direct users back to the stable version.
- Fix and Redeploy: Resolve the issues in the canary version before attempting another rollout.
Pros and Cons
Pros:
- Minimized Risk: Only a small subset of users are affected if issues arise.
- Real-world Testing: Gather data on performance and user experience in a live environment.
- Flexible Rollout: Control the pace of the deployment based on confidence levels.
Cons:
- Complex Setup: Requires additional tools and configurations.
- Monitoring Overhead: Needs robust monitoring and analysis.
- Inconsistent User Experience: Different users may have different experiences.
Is Canary Deployment Right for You?
Canary deployments are ideal when you want to test new features or changes in production with minimal risk. It's suitable for organizations that can invest in additional tooling and have strong monitoring capabilities.
Best Practices for All Strategies
To ensure successful deployments, regardless of the strategy, consider implementing the following best practices:
Comprehensive Monitoring
Why It's Important:
- Early Issue Detection: Quickly identify problems before they impact more users.
- Performance Analysis: Understand how changes affect application performance.
- User Experience: Make sure that users are not negatively impacted by the deployment.
Tools to Use:
- Prometheus: For collecting metrics from your applications and Kubernetes.
- Grafana: For visualizing data and creating dashboards.
- Elastic Stack (ELK): For log aggregation and analysis.
Implementing Monitoring:
- Set Up Alerts: Configure alerts for critical metrics like error rates and latency.
- Dashboard Creation: Build dashboards to visualize key performance indicators.
- Regular Reviews: Analyze data regularly to spot trends and anomalies.
Implementing Health Checks
Readiness Probes:
- Purpose: Indicate when a pod is ready to receive traffic.
- Benefit: Prevents traffic from being sent to pods that are not fully initialized.
Liveness Probes:
- Purpose: Detect when a pod is unhealthy and needs to be restarted.
- Benefit: Improves application reliability by automatically recovering from failures.
Example Configuration:
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
Graceful Shutdowns
Why It's Important:
- Prevent Data Loss: Allows in-flight requests to complete before terminating.
- Improve User Experience: Users don't experience abrupt disconnections.
- Maintain Stability: Reduces the risk of cascading failures.
Implementing Graceful Shutdown:
- Configure Termination Grace Period: Set
terminationGracePeriodSecondsin your pod spec. - Handle SIGTERM Signal: Ensure your application listens for termination signals and shuts down gracefully.
- Connection Draining: Use readiness probes to remove a pod from service before shutting down.
Example Configuration:
spec:
terminationGracePeriodSeconds: 30Automate Rollbacks
Why It's Important:
- Quick Recovery: Minimize downtime by swiftly reverting to a stable version.
- Reduce Manual Errors: Automation reduces the risk of mistakes during a rollback.
Implementing Rollbacks:
- Version Control: Use image tags or versions in your deployments.
- Deployment History: Kubernetes keeps a history of deployments which can be used to roll back.
- Commands to Use:
# Check deployment history
kubectl rollout history deployment/my-app
# Roll back to previous revision
kubectl rollout undo deployment/my-app
Secure Your Pipeline:
- Image Security: Scan container images for vulnerabilities.
- Access Control: Use Kubernetes RBAC to control who can deploy updates.
- Secrets Management: Securely manage sensitive information using Kubernetes Secrets.
Implementing Security Measures:
- Regular Scans: Integrate security scanning into your CI/CD pipeline.
- Least Privilege Principle: Grant only necessary permissions to users and services.
- Encryption: Use TLS for all communication and encrypt sensitive data at rest.
Comparing Deployment Strategies
To help you decide which deployment strategy suits your needs, here's a detailed comparison:
Aspect | Rolling Updates | Blue/Green Deployments | Canary Deployments |
|---|---|---|---|
Downtime | None | None | None |
Resource Usage | Efficient, uses existing resources without significant overhead. | High resource usage, requires double the infrastructure to run two environments simultaneously. | Moderate resource usage, requires additional resources for canary instances but less than Blue/Green deployments. |
Complexity | Low to moderate complexity, utilizes Kubernetes' built-in capabilities without needing extra tools. | Moderate complexity, involves managing and synchronizing two separate environments. | High complexity, requires advanced traffic management and monitoring tools like Istio or Linkerd. |
Risk Level | Moderate risk, as issues may gradually affect users during the rollout if not detected early. | Low risk, easy to switch back to the previous environment if issues arise, minimizing user impact. | Low risk, issues are limited to a small subset of users, allowing for controlled testing and quick adjustments. |
Rollback Ease | Moderate ease of rollback, can be done but may have already impacted users. | High ease of rollback, switching back to the previous environment is straightforward and quick. | High ease of rollback, can quickly redirect traffic back to the stable version with minimal disruption. |
Deployment Speed | Slower deployment, as updates are applied incrementally to each pod. | Fast deployment once the switch is made, but requires time for thorough testing before switching. | Variable deployment speed, can be adjusted based on confidence levels and performance during initial rollout. |
Ideal Use Cases | Suitable for standard applications needing gradual updates without significant resource overhead. | Ideal for critical applications where zero downtime and easy rollback are essential, and resources are available for two environments. | Best for introducing new features or versions where you want to test performance and user response with minimal risk before a full rollout. |
Examples of Use | Commonly used for regular application updates, minor version upgrades, and services that can tolerate incremental changes. | Used for major version releases, significant changes that require isolated testing, and when a quick and safe rollback mechanism is necessary. | Used by companies like Google for features in services like Google Maps, testing new functionalities with a small user base before wider release. |
Tooling Required | Requires minimal tooling, leveraging Kubernetes' native deployment features. | May require additional management tools for environment synchronization but generally uses standard Kubernetes resources. | Requires additional tools like Istio or Linkerd for traffic routing and advanced monitoring solutions for performance tracking and feedback. |
User Experience | Generally consistent, but users may experience issues if problems arise during the rollout before they are detected and addressed. | Consistent user experience, as the switch between environments is seamless and users are unlikely to notice the transition if all goes well. | Variable user experience, as different users may access different versions, acceptable for testing but may require communication to users. |
Conclusion
Bringing It All Together
Deploying applications without downtime is critical for maintaining user satisfaction and business continuity. By understanding and implementing the right deployment strategy, you can minimize risks and ensure a smooth user experience.
- Rolling Updates: Ideal for most applications, offering zero downtime with efficient resource usage.
- Blue/Green Deployments: Best for critical applications where a quick rollback is essential, despite higher resource costs.
- Canary Deployments: Perfect for testing new features with real users while limiting exposure to potential issues.
Next Steps
- Assess Your Needs: Consider your application's requirements, resource availability, and risk tolerance.
- Experiment: Try out different strategies in a test environment to see which one fits best.
- Implement Best Practices: Incorporate monitoring, health checks, and security measures regardless of the strategy chosen.
- Stay Informed: Keep learning about new tools and updates in Kubernetes that can aid in deployment strategies.
Need Help with Your Deployments?
If you're facing downtime issues or want to optimize your application's deployment process, we're here to help. At KubeNine, we specialize in resolving deployment challenges and implementing strategies that ensure zero downtime. Let us handle the complexities so you can focus on what matters most—your product.
Thank you for taking the time to read this guide. I hope it has provided you with valuable information on achieving zero downtime with Kubernetes deployment strategies. Deployments don't have to be a source of stress—with the right approach and tools, you can update your applications confidently and efficiently.
If you have any questions or would like to share your experiences, please feel free to leave a comment or contact us at KubeNine. We're always happy to help.
Checkout our article to manage your kubernetes secrets with ease: https://www.kubeblogs.com/manage-your-kubernetes-secrets-securely-directly-from-the-web-browser/