
On this page
Test your LLM applications right!

What’s the biggest challenge when building applications, whether they’re web-based, native, LLM-powered, or anything else? Testing! Every time you make a change, you need to ensure the application still functions smoothly and that your new features haven’t broken any part of the flow. To simplify this, we rely on testing frameworks like pytest, vitest, and others to help catch bugs or feature breaks early on.
But as the ecosystem evolves and more applications integrate AI or LLM capabilities, are these testing frameworks evolving to keep up? The challenges are no longer limited to simple Pass or Fail test cases; now we have to account for non-deterministic LLM responses. At Kubenine, we discovered a better solution for evaluating LLM applications in a very familiar way, integrating Pytest and Vitest for LangSmith evaluations.
Challenges in Testing LLM Applications
When it comes to testing software applications, traditional methods are quite straightforward, as demonstrated below in the typical test case for an API:
import requests
import pytest
# URL of the API endpoint
API_URL = "https://api.example.com/endpoint"
# Test case to check API response status and content
def test_api_response():
# Send GET request to the API
response = requests.get(API_URL)
# Check if the response status code is 200
assert response.status_code == 200, f"Expected status code 200 but got {response.status_code}"
# Check if the response contains "code" == "success"
response_json = response.json()
assert response_json.get("code") == "success", f"Expected 'code' to be 'success' but got {response_json.get('code')}"
In this example, the test case checks if the API responds with a 200 HTTP status and contains a success code. This is a deterministic test, meaning that the output is predictable. The response will always be the same unless there's an error in the API.
When testing such applications, the outputs are relatively simple and easily validated against a predefined set of expectations. If the response meets the criteria, such as a 200 status code and a "code" key equal to "success", the test passes. If not, the test fails. This simplicity and predictability make testing in non-LLM applications manageable.
However, when we turn our attention to LLM-based applications (like chatbots, generative models, and content creators), the situation changes drastically.
Let’s take a look at a simple LLM chatbot example:
import openai
class LLMChatbot:
def __init__(self, model="gpt-4"):
self.model = model
self.api_key = "your-openai-api-key" # Make sure to set up your API key
def query(self, prompt: str):
response = openai.Completion.create(
model=self.model,
prompt=prompt,
max_tokens=100,
api_key=self.api_key
)
return response.choices[0].text.strip()
In this example, we’ve created a simple LLM chatbot that interacts with the OpenAI API. The query method sends a prompt to the model and retrieves a response. However, testing such an application introduces new challenges that we don’t face when testing traditional, non-LLM applications.
Why is Testing LLM Applications Difficult?
- Non-Deterministic Responses: Traditional software is deterministic; given the same inputs, it always produces the same outputs. LLMs, however, are probabilistic and generate different responses for the same input. This unpredictability complicates testing, as exact match assertions no longer suffice.For example:Both answers are valid, but phrased differently. This makes exact matching ineffective in testing LLM outputs.
- "The capital of France is Paris."
- "Paris is the capital of France."
- Complexity in Output Evaluation: Traditional applications usually test the output through direct comparisons. With LLMs, responses may be semantically correct but formatted differently. Therefore, advanced evaluation strategies are necessary, such as semantic comparison rather than string matching.
- Subjective Judgment: LLM-generated content often includes subjective elements. For instance, a chatbot might offer multiple valid answers to a creative prompt or recommend movies based on user preferences. These subjective elements make it harder to define deterministic tests.
- External System Dependencies: LLM applications often interact with external systems (e.g., APIs or databases), which adds complexity. The LLM’s output might depend on real-time data or other integrations, requiring tests to account for both LLM behavior and external system interactions.
What is LangSmith?
LangSmith is a platform built specifically to help developers test, debug, and optimize applications powered by Large Language Models (LLMs). It enables users to track and visualize the performance of their LLM-based applications with deep observability, providing a range of features such as logging inputs and outputs, evaluating responses, and managing feedback. LangSmith is designed to streamline the development process of LLM applications by making the evaluation process simpler, more collaborative, and more insightful, all while integrating seamlessly with popular development tools and workflows.
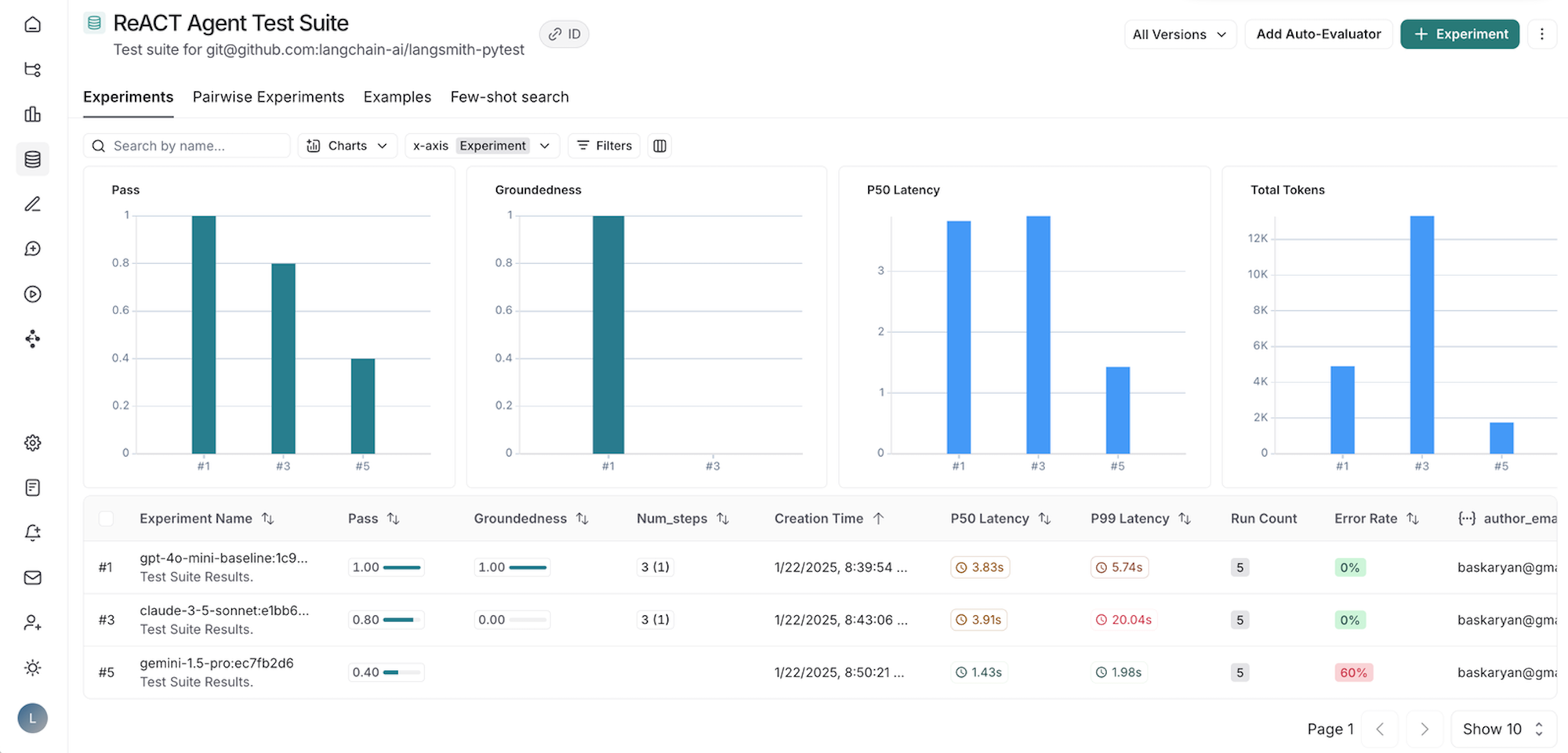
Pytest Integration with LangSmith
Evaluations (evals) are an essential part of building reliable and high-quality LLM applications. They help you assess the performance of your application, ensuring that quality remains consistent as you make updates. If you come from a software engineering background, you’re likely familiar with using tests for this purpose. To extend this familiar interface, we have found a new way to run evals using LangSmith’s Pytest and Vitest/Jest integrations.

Why Use Testing Frameworks for LLM Evals?
If you’re already using Pytest or Vitest/Jest to test your application, the new LangSmith integrations give you the flexibility, familiarity, and runtime behavior of Pytest/Vitest with the observability and sharing features of LangSmith. These integrations use the exact same developer experience you’re used to, and have the following benefits:
- Debug your tests in LangSmith: Applications that use LLMs have additional complexity when debugging due to their non-deterministic nature. LangSmith saves inputs/outputs and stack traces from your test cases to help you pinpoint the root cause of issues.
- Log metrics (beyond pass/fail) in LangSmith and track progress over time: Typically, testing frameworks focus only on pass/fail results, but testing LLM applications often requires a more nuanced approach. You may not have hard pass/fail criteria; rather, you want to log results and see how your application improves over time. With LangSmith, you can log feedback and compare results over time to prevent regressions and ensure that you're always deploying the best version of your application.
- Share results with your team: Building with LLMs is often a team effort. We commonly see subject matter experts involved in the process of prompt creation or when creating evals. LangSmith allows you to share results of experiments across your team, making collaboration easier.
- Built-in evaluation functions: If you’re using Python, LangSmith offers some built-in evaluation functions to help when checking against your LLM’s output. For example,
expect.edit_distance()is used to compute the string distance between your test’s output and the reference output provided.
Getting Started with Pytest
To track a test in LangSmith, add the @pytest.mark.langsmith decorator.
# tests/test_sql.py
import openai
import pytest
from langsmith import wrappers
from langsmith import testing as t
oai_client = wrappers.wrap_openai(openai.OpenAI())
@pytest.mark.langsmith
def test_offtopic_input() -> None:
user_query = "whats up"
t.log_inputs({"user_query": user_query})
expected = "Sorry that is not a valid question."
t.log_reference_outputs({"response": expected})
actual = generate_sql(user_query)
t.log_outputs({"response": actual})
with t.trace_feedback():
instructions = (
"Return 1 if the ACTUAL and EXPECTED answers are semantically equivalent, "
"otherwise return 0. Return only 0 or 1 and nothing else."
)
grade = oai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": instructions},
{"role": "user", "content": f"ACTUAL: {actual}\nEXPECTED: {expected}"},
],
)
score = float(grade.choices[0].message.content)
t.log_feedback(key="correctness", score=score)
assert actual
assert scoreKick off the tests like you usually would:
pytest testsThis will run like any other pytest test run and also log all test case results, application traces, and feedback traces to LangSmith.
Conclusion
Testing LLM-powered applications presents unique challenges due to their non-deterministic nature, subjectivity, and external system dependencies. However, by integrating LangSmith with familiar testing frameworks like Pytest and Vitest, developers can streamline the evaluation process, track metrics, and improve collaboration across teams. LangSmith offers deep observability, making it easier to debug issues and track improvements over time.
At KubeNine, we understand how crucial it is to maintain high-quality standards when developing LLM applications. Want to optimize your LLM testing workflow or need assistance in building robust LLM applications? Let Kubenine help you simplify things and equip you with the full potential of your AI-powered systems.