Table of Contents
Introduction
Podcasts, video calls, and voice calls produces hours of speech every day. Turning that speech into text is now routine for meetings, customer-support calls, and more. A simple audio to text tool can help us capture conversations on meetings, phone or our smart watch - once recorded we can transcribe it and give it to things like chatgpt for all the wonderful insights possible.
This project demonstrates how quickly we can build ready to use tools using Streamlit. As a showcase, we built an AI-powered Audio Transcription Tool that uses speech recognition models to convert audio into text with high accuracy. The app addresses a common limitation we found in nearly every transcription tool we evaluated — strict limits on audio length or file size, which made them impractical for long conversations.
We've open-sourced this project for you all to try out: https://github.com/kubenine/Audio-to-text
What is Audio Transcription?
Audio transcription is the process of converting spoken language in an audio file into written text. While traditionally done manually, newer transcription tools use advanced speech recognition technologies to automate this process.
The key benefits of automated transcription include:
- Time Efficiency: Transcribe hours of audio in minutes rather than days
- Cost Reduction: Eliminate expensive manual transcription services
- Searchability: Makes audio content fully searchable
- Accessibility: Creates accessible content for hearing-impaired users
- Data Analysis: Enables text analysis of spoken content
How Our Transcription Tool Works
Our Audio Transcription Tool follows a straightforward process to convert your audio to text:
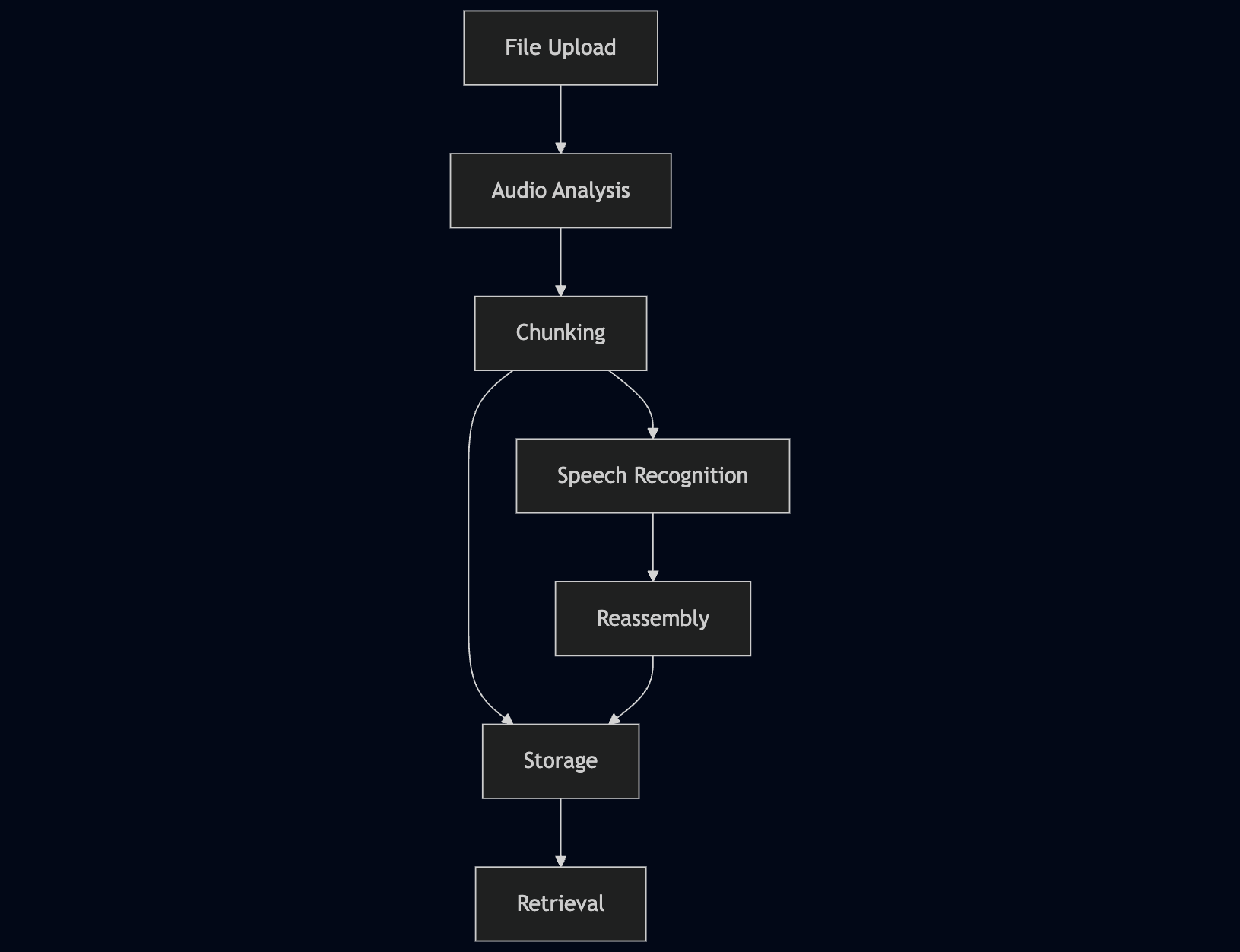
Audio Processing Flow:
- File Upload: Users upload audio files through a simple interface
- Audio Analysis: The system analyzes the audio quality and format
- Chunking: Larger files are automatically split into manageable chunks
- Speech Recognition: Advanced AI models convert speech to text
- Reassembly: Results from all chunks are combined into a final transcript
- Storage: Both the audio file and transcript are securely stored
- Retrieval: Users can view, search, and download transcripts
Handling Complex Audio
The tool intelligently manages challenging audio scenarios:
- Long Recordings: Breaking files into chunks for efficient processing
- Multiple Speakers: Distinguishing between different voices
- Background Noise: Filtering out unwanted sounds
- Accents and Dialects: Adapting to different speaking patterns
- Technical Terms: Handling domain-specific vocabulary
Architecture Overview
Our transcription solution is built on a newer, scalable architecture:
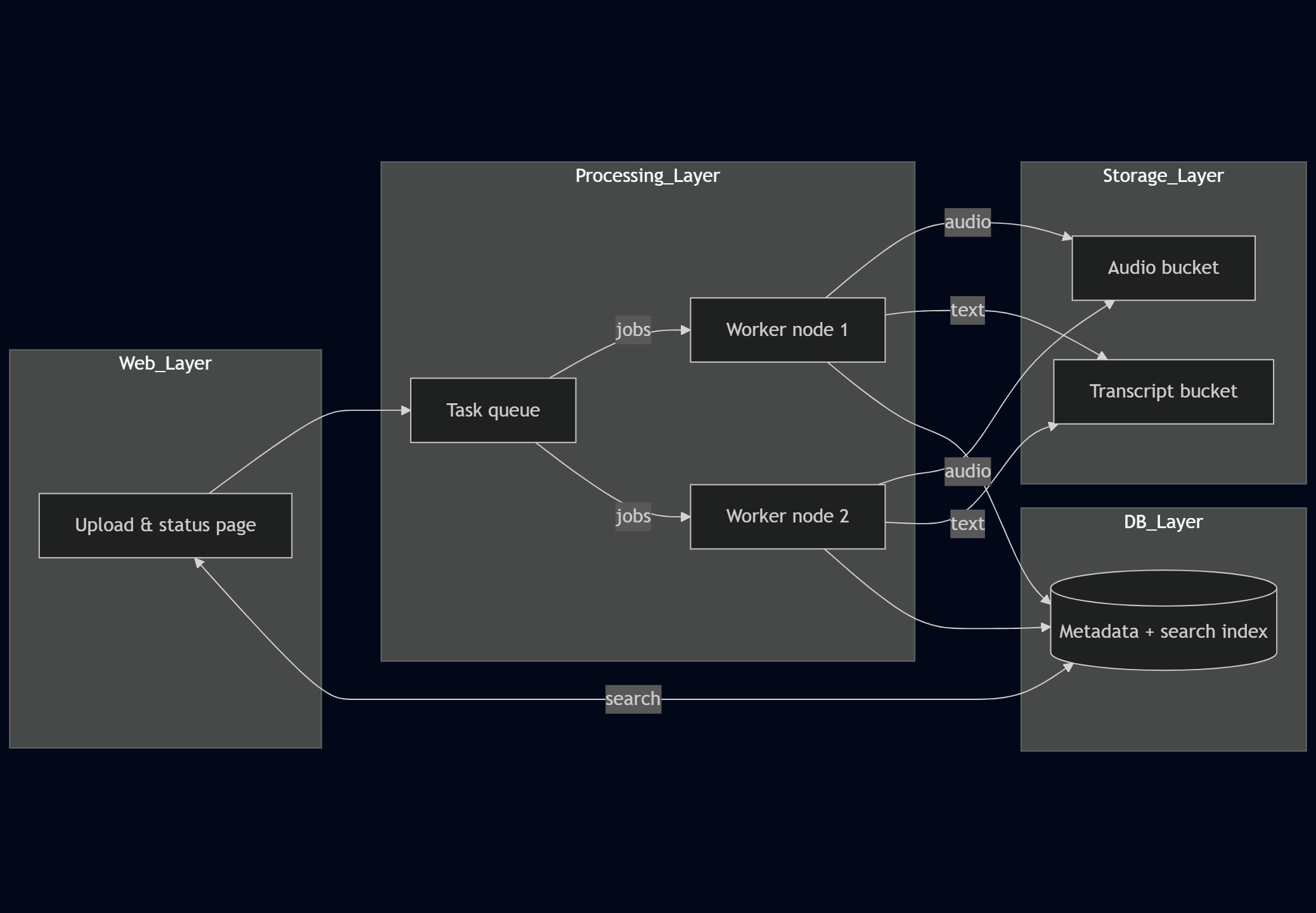
Key Components:
- User Interface Layer: An intuitive web interface for uploading and managing audio files
- Processing Layer: Asynchronous task handling for scalable processing
- Storage Layer: Secure storage for both audio files and transcriptions
- Database Layer: Efficient metadata management and search capabilities
Advanced Features:
- Asynchronous Processing: Transcribe multiple files simultaneously
- Background Processing: Continue working while transcription happens in the background
- Failure Recovery: Automatic retries and error handling
- Scalable Design: Handles high volumes of concurrent transcriptions
Implementation Considerations
When implementing an audio transcription solution, several factors should be considered:
Technical Considerations:
- Audio Quality: The better the audio quality, the more accurate the transcription
- File Size Management: Efficient handling of large audio files
- Processing Power: Computing resources needed for speech recognition
- Security: Ensuring data privacy throughout the transcription process
- Scalability: Handling peak loads and growing user bases
Practical Applications:
- Content Creation: Generate transcripts for videos and podcasts
- Research: Convert interviews and focus groups into analyzable text
- Business Intelligence: Extract insights from customer calls
- Accessibility: Make audio content available to hearing-impaired users
- Compliance: Create records of meetings and conversations for regulatory purposes
Deployment Options
Our Audio Transcription Tool offers you three ways to run it: on your laptop, in the cloud, or inside a Docker cluster.
- Local Installation: Perfect for individual users or small teams who need a self-contained solution. The application runs on your own hardware with minimal setup requirements.
- Cloud Deployment: Ideal for businesses needing scalability and high availability. The system can be deployed on major cloud platforms with automatic scaling based on demand.
- Docker Containerization: If you already run Kubernetes (or another orchestrator), you can deploy the Docker image as-is—no extra configuration needed.
Best Practices for Audio Transcription
To get the most accurate transcriptions from our tool:
- Ensure Good Audio Quality: Record in quiet environments with minimal background noise
- Use Proper Equipment: Quality microphones produce better results
- Speak Clearly: Clear pronunciation improves accuracy
- Format Appropriately: Use supported audio formats for best results
- Break Up Long Recordings: Consider recording in smaller segments
- Post-Processing: Review and edit transcripts for any inaccuracies
Conclusion
Audio transcription technology transforms how we work with spoken content, making it searchable, accessible, and more valuable. Our Audio Transcription Tool brings the power of newer AI to your audio files, saving time and unlocking new possibilities for your content.
For consultation on implementing such solutions or other scalable application architecture challenges, contact our team at KubeNine.
Recent Posts